
Project > Programming Environment
Programming Environment
Developing FPGA accelerators traditionally comes with a lot of low-level legwork for the developer, particularly in coordinating with the platform and hardware vendors. To make their lives easier – and to improve the portability of their FPGA accelerators – a range of different runtime systems have emerged. These offer high-level abstractions for FPGA accelerators, making it much easier to retarget specific hardware – leaving the developer to focus their efforts elsewhere.
We brought several of these high-level systems for programming FPGAs together for EuroEXA, integrating them into our system-firmware. That means these systems can take advantage of multiple interconnected FPGAs in a uniform way. Effectively, EuroEXA brings FPGA programming environments to the large scale, by putting together all the pieces needed to bring an accelerator from 1 FPGA board to thousands, with much less effort than ever before.
Maxeler MaxCompiler & MaxJ
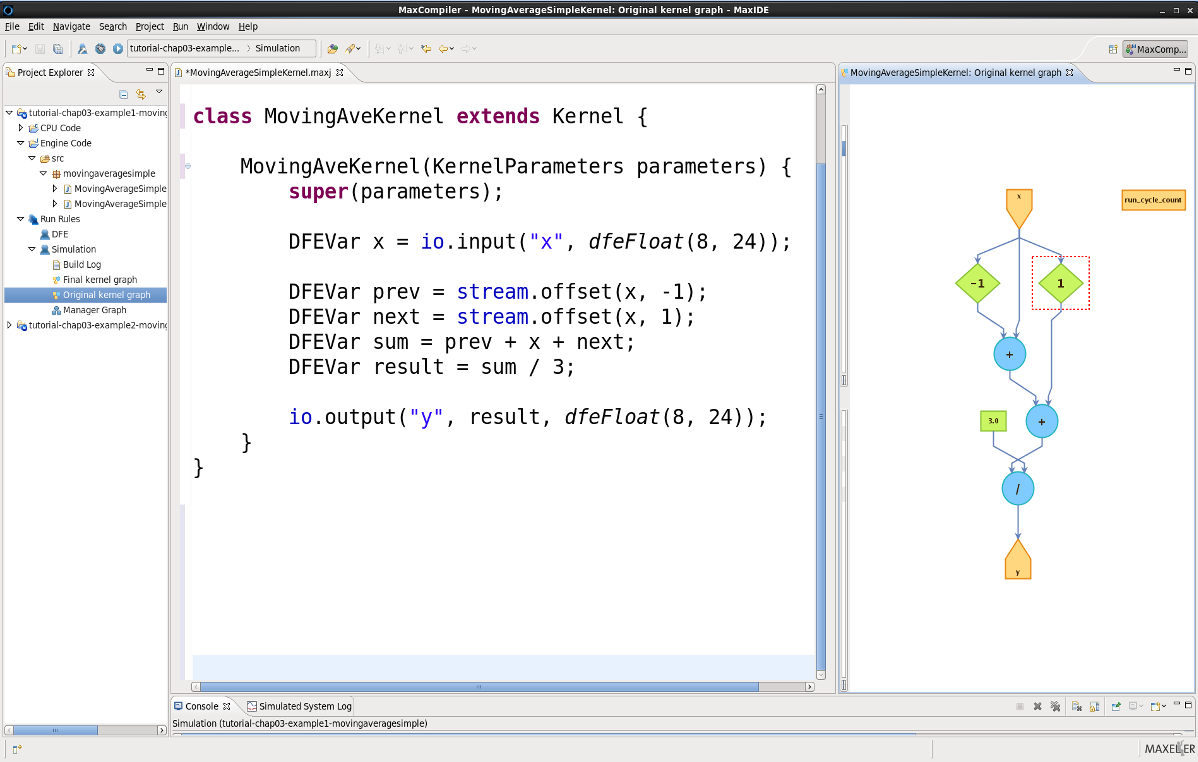
Maxeler’s MaxCompiler provides a high-level design environment for FPGA-based accelerators with a difference. It stands apart from most traditional hardware description languages (HDLs) which provide a very low level of abstraction, and from High-Level Synthesis (HLS) which tries to present hardware development as conventional software development, like C/C++.
With MaxJ, Maxelar offers a different route – with a high-level approach that maintains as much focus on hardware as necessary to support fully optimised implementations. As such, its abstraction level is somewhere between HDL and HLS.
MaxJ abstracts and automates many low-level details, like pipelining and scheduling of the datapath, but the developer maintains full control over all architecture details. This includes a high-level view of the hardware architecture, in terms of its available IO bandwidth and its hardware resources – vital details that allow the developer to plan the ideal data-path architecture in a simple spreadsheet.
So, instead of applying optimisations piece by piece, the developer starts with a simple and clear model of the architecture, helping them understand and estimate their solution’s performance before they’ve written a single line of code. This provides the developers with a clear path to a fully optimised solution early in the design process, with the tools that not only support many hardware-centric optimisations, but also offer the resilience that comes with high-level constructs for checking errors or correcting hardware.
MaxJ’s code is even free from vendor-specific constructs, removing the fundamental barriers to moving code between target devices. While some code might have to be re-optimised for a new target device with different characteristics, it avoids vendor lock-in.
OmpSs
Many HPC and non-HPC applications are written in C/C++, before being ported to OpenMP or OmpSs for homogeneous systems. OmpSs@FPGA is the extension of the OmpSs programming model and tools, allowing us to port these applications to FPGA-based heterogeneous systems with low overhead and high performance.
OmpSs@FPGA offers several features that support and improve programmability and performance on those SMP and FPGA device-based heterogeneous systems:
Task execution model:
It easily supports heterogeneous task-based parallel programming for SMP with FPGA devices – ensuring that it is transparent for the programmer, allowing FPGA and SMP tasks to execute in parallel. It even provides dynamic dataflow task-based execution support, as it isn’t limited to a static number or order of the tasks executed in the FPGA accelerators.
It automatically manages all the data transfers and task synchronization, so the programmer doesn’t need to worry about the device driver in terms of controlling data communication, managing tasks and data inside the FPGA, or transfers and synchronizations of data memory.
AutoVivado plugin – developed by the BSC team, this plugin generates user-annotated FPGA task accelerators and integrates them into a vendor project. This gives OmpSs@FPGA the capability to help generate FPGA bitstreams from C/C++ code which are transparent to the programmer, on top of the FPGA vendor tools. As such, the programmer doesn’t need to use vendor-specific programming tools, acceleration generation and error-prone low-level communication. With just one high-level click annotation in the code, the programmer can compile and obtain the SMP-executable or FPGA bitstream.
Programmability & Productivity:
OmpSs@FPGA code is vendor-agnostic and portable – so the same application can be executed using a different hardware configuration in the same platform, just by configuring the runtime environment variables. This gives programmers and researchers the chance to perform design-space explorations easily.
The toolchain allows advanced OmpSs@FPGA programmers to specify differently tuned task definitions for the same function code, offering the opportunity for the programmer to optimise code for FPGA accelerators or for SMP code using specific libraries, like OpenBlas.
The toolchain also allows advanced programmers to control specific data transfer easily, enabling them to perform SMP-to-FPGA or FPGA-to-SMP data transfers from inside the FPGA with C code (or using memcpy operations). As such, they can use blocking-optimisation techniques for applications with large workloads, as they could with SMP code.
Paraver/Extrae Tracing – OmpSs@FPGA includes tools for generating and analysing execution traces. By default, the trace includes SMP execution information, as well as data transfer and computation execution information of the FPGA task execution. This allows programmers to focus on the bottlenecks of the applications. Indeed, our toolchain also allows programmers to instrument the FPGA task, ensuring they can generate user events in the execution trace, allowing a deeper analysis of the applications.
OpenStream
OpenStream is a task-parallel data-flow programming model, which works as an extension to OpenMP. It’s designed for efficient and scalable data-driven execution, with shared-memory programming for fast prototyping. The model essentially follows the OpenMP syntax, though the programmer needs to provide additional information using a dedicated syntax to take advantage of OpenStream optimisations. This allows programmers to take advantage of efficient scheduling and placement strategies, by expressing arbitrary dependence patterns, which are used by the runtime system to exploit parallel task, pipeline and data.
Heterogeneous work and data placement
OpenStream relies on various forms of work-stealing (including random, hierarchical and data-dependence based) and work-pushing for it to assign tasks to idle processing resources dynamically. In heterogeneous systems, scheduling with work-stealing alone leads to poor data locality – in particular when memory access is not uniformly shared across computing resources.
OpenStream implements a novel scheduling heuristic that relies on the metadata information provided by the run-time to make decisions on task and data placement while the program executes. This approach is capable of executing work on CPUs, GPUs and FPGAs at the same time, with load balancing that reacts dynamically to the available parallelism as the program executes.
Optimised scheduling and work granularity
When OpenStream programmes are regular – like, for instance, static control programmes – they can be statically optimised using polyhedral compilation techniques. This coarsens work granularity (tiling) or can help identify more efficient work schedules to implement at runtime – for example, to minimise the memory requirements for program execution.
PSyclone
PSyclone is a code generation and transformation system, developed to support domain-specific languages (DSLs) for finite element, finite volume and finite difference codes. DSLs offer programmers the advantage of focusing separately on the code that captures the underlying science (the science code) and the code that deals with the performance characteristics of the platform.
In massively parallel and novel architectures like ours, this separation is crucial as it allows HPC experts to work on the parallelisation and performance portability of the platform, without having to alter the original science code – or worrying about any optimisations performed for unrelated platforms.
With PSyclone, these platform-specific considerations are encoded by the HPC expert as a recipe of transformations that specify how to generate optimised code for the required target.
By generating the complex, platform-specific parallel and performant code, PSyclone leaves the domain-specific scientists free to concentrate on the science aspects of the model – writing code that will scale from a single processing unit or core, up to a complex architectures with thousands of accelerator units.
As part of the EuroEXA project, we are developing a PSyclone back-end to help us generate FPGA accelerator code. This technology, combined with a EuroEXA-specific transformation recipe, is then being used to port the NemoLite2D application to the EuroEXA platform.
PSyclone is a BSD3-licenced open source project being developed by a community of developers on GitHub (see https://github.com/stfc/PSyclone). You can find more information in the PSyclone User Guide: https://psyclone.readthedocs.io/.
GPI
GASPI is a programming model designed with a focus on asynchronous and one-sided communication. As such, it allows communication with less synchronization bottlenecks, together with an overlap of communication and computation.
Semantically, the GASPI API is very similar to the asynchronous MPI communication commands – though, compared to MPI, GASPI implements a weak form of synchronization via notifications. In addition to the communication request, where the sender posts a PUT request for transferring data, the sender also posts a notification with a given value. The order of the request and the notification is guaranteed to be maintained, as the notification semantic is complemented with routines which wait for an update of the notification – therefore acknowledging the arrival of new data.
With a partitioned global address space in mind, GASPI exploits the communication hierarchies. GASPI is thread-safe and encourages thread-based (such as OpenMP) or task-based (such as OmpSs) approaches in shared memory regions. This means that different communication models can be used, depending on whether the communication is between local memory or remote distributed memory – which sets it apart from the UNIMEM programming model.
MPI
The MPI standard is the traditional method for developing HPC applications that can scale up to thousands or millions of nodes in a supercomputer. The EuroEXA project accelerates MPI with the UNIMEM fast network, allowing legacy applications to take advantage of our hardware without unnecessary overheads.
To achieve this, we are optimising various parts of the MPIS library to leverage custom hardware acceleration. Moreover, we are integrating MPI with existing runtimes for FPGA accelerator development, making it much easier to harness these accelerators to tackle traditional HPC problems.